ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
OLAP和OLTP区别
上面那句话是来自ClickHouse中文官网
其中OLAP这个词熟悉又陌生,还有一个对应的叫做OLTP,我们简单介绍一下两者区别。
OLTP(on-line transaction processing)翻译为联机事务处理
OLAP(On-Line Analytical Processing)翻译为联机分析处理
OLTP主要对数据做增删改操作
OLAP主要对数据做查操作
OLTP用于在业务系统中,直接产生存储业务数据,如电子商务,银行,证券,一般数据量较小,要求操作实时性高
OLAP主要集中业务数据,进行统一的综合分析,分析的数据量一般巨大,不能做到很好地实时性
OLAP分类
OLAP还可以分为ROLAP(关系型联机分析处理)以及MOLAP(多维联机分析处理)
ROLAP
完全基于关系模型进行存储,只是根据分析的需求对模型的结构和组织进行了优化,代表有MPP分布式数据库,以及基于Hadoop的Spark,Hive
因为ROLAP是实时来需求,实时进行计算,所以在数据量庞大的情况下速度会变得不能接受,而传统数据库无法支持大规模集群和PB级别数据量,所以这时候出现了MMP(大规模并行)数据库,这种数据库解决了一部分可扩展性问题,在支持的数据体量上有了很大的提升,但是在节点数量很大的时候就算再提升集群规模性能也不会有很大提升
基于Hadoop的Spark对硬件要求很低,但是计算量级达到一定程度无法秒级响应,并且因为是基于内存计算容易出现内存溢出等问题
MOLAP
MOLAP理念就是既然计算能力不够能秒级返回结果,那我就按照一些维度先算好数据,到时候直接返回,优点就是同等资源下支持的数据体量更大,并发更多,但是当表的维度越多越复杂,需要的磁盘存储空间越大,构建cube也越复杂。常见的MOLAP服务器有SSAS,Kylin
Kylin则是目前技术较为先进的一款成熟产品,基于Hadoop框架,Cube以分片的形式存储在不同节点上,Cube大小不受服务器配置限制,所以具备很好的可扩展性和对服务器要求很低,在扩容成本上就非常低廉。另外为了控制整体Cube的大小,Kylin给客户提供了建模的能力,即用户可以根据自身需要,对模型种的维度以及维度组合进行预先的构建,把一些不需要的维度和组合筛选掉,从而达到降低维度的目的,减少磁盘空间的占用。
从可扩展性上看:
Kylin=Impala/Spark>MPP数据库>传统数据库;
从对硬件要求上看:
传统数据库>MPP数据库>Impala/Spark>=Kylin;
从响应效率上来看:
不同的数据量、并发数,响应效率差别不一,但可以确定的是,要计算的数据量越大,并发的用户数越多,同等资源情况下预计算的响应效率会越发明显。

ClickHouse
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)
安装与部署
系统是m1 Mac,目前还不能原生的支持ClickHouse,找了个centos 7的服务器,下面我们先来安装部署一下ClickHouse。
首先检查我们的系统是否支持
1 | grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported" |
输出前面的结果:SSE 4.2 supported 即为支持
centos安装命令如下:
1 | 首先我们添加安装源 |
如果想使用最新的版本,请用testing替代stable
运行命令安装:
1 | sudo yum install clickhouse-server clickhouse-client |
启动(默认是./config.xml所以需要在相应目录下启动)
1 | sudo service clickhouse-server start |
服务端日志文件路径:/var/log/clickhouse-server/
默认配置文件在:/etc/clickhouse-server/config.xml
运行的时候,配置文件会自动合并/etc/clickhouse-server/config.d目录下的xml文件
在控制台启动:
1 | 实际上还有config.d目录下的xml配置文件,需要注意下 |
导入示例数据集
下面我们做一个官网的一个数据集测试,了解一下基础的如何导入数据以及查询
1 | curl https://datasets.clickhouse.tech/hits/tsv/hits_v1.tsv.xz | unxz --threads=`nproc` > hits_v1.tsv |
这两个文件数据量有10G左右,我们通过head命令提取部分数据即可
head -n 100000 hits_v1.tsv > hits_v2.tsv
head visits_v1.tsv -n 50000 > visits_v2.tsv
准备库表
登录clickhouse客户端
交互模式:
1 | clickhouse-client |
启用多行查询:
1 | clickhouse-client -m |
以批处理模式运行查询:
1 | clickhouse-client --query='SELECT 1' |
从指定格式的文件中插入数据:
1 | clickhouse-client --query='INSERT INTO table VALUES' < data.txt |
这里我们建立一个库名叫做adtiming
1 | clickhouse-client --query "CREATE DATABASE IF NOT EXISTS adtiming" |
建表语法要复杂的多,建表文档
分别创建hits表以及visits表
1 | CREATE TABLE adtiming.hits_v1 |
1 | CREATE TABLE adtiming.visits_v1 |
我们可以看到两张表分别使用了不同的表引擎,其中 hits_v1使用 MergeTree引擎,而visits_v1使用 Collapsing引擎
对于我们需要不同功能的表或者不同使用途径的表Clickhouse具有不同的表引擎来应对,表引擎文档 表引擎官方文档
MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。所以相当于这种表结构适用于插入操作较多,并且一次插入数据较大的情况。
CollapsingMergeTree 会异步的删除(折叠) Sign 有 1 和 -1 且其余所有字段的值都相等的成对的行。没有成对的行会被保留。
每个引擎实际上就代表一种需求,比如CollapsingMergeTree就是去重作用。
插入数据
1 | clickhouse-client --query "INSERT INTO adtiming.hits_v1 FORMAT TSV" --max_insert_block_size=100000 < hits_v2.tsv |
检验插入是否成功(如果直接用大数据量文件可能会导致插入失败)
1 | clickhouse-client --query "SELECT COUNT(*) FROM adtiming.hits_v1" |

查询
下面对数据进行简单的查询
1 | SELECT |
查询结果如下图所示

简单思考
官网实例这个sql第一眼看上去感觉有点怪,因为group by后面的字段是别名字段URL,这个在Hive或者Mysql中应该都是不可以的,group by后面直接使用别名是会报错的,我们可以从SQL的执行顺序出发来看这个问题。
Mysql的实行顺序:
(1) FROM
(2) ON
(3)
(4) WHERE
(5) GROUP BY
(6) HAVING
(7) SELECT
(8) DISTINCT
(9) ORDER BY
(10) LIMIT
Hive执行顺序
from … on … join … where … group by … having …
select … distinct … order by … limit
上面展示了Hive以及Mysql中都是group by在select后面,所以group by不能使用别名来操作,但是order by是可以直接使用别名的,说明ClickHouse的SQL执行和常见的数据库不太一样,具体差别都有什么我们后面学习到了再来总结。
ClickHouse表引擎
首先我们了解到ClickHouse的核心引擎是MergeTree系列引擎,因为MT系列引擎支持了像数据按照主键排序,指定分区键实现分区,数据副本,数据采样等功能,这是其他像Log,Integration引擎所不具备的功能,所以我们先学习MergeTree系列引擎,也是最难的。
MergeTree系列引擎种类繁多,有以下MergeTree、ReplacingMergeTree、SummingMergeTree、AggregatingMergeTree、CollapsingMergeTree、VersionedCollapsingMergeTree、GraphiteMergeTree 等 7 种不同类型的 MergeTree 引擎,以及其对应支持副本的Replicated*系列引擎

下面我们介绍每一种引擎的业务场景
ReplacingMergeTree: 在后台数据合并期间,对同一个分区内具有相同 排序键 的数据进行去重操作,ReplacingMergeTree 适用于在后台清除重复的数据以节省空间,但是它只能保证同一个分区内没有重复的数据出现
1 | CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] |
ENGINE = ReplacingMergeTree([ver]),其中ver为选填参数,它需要指定一个UInt8/UInt16、Date或DateTime类型的字段,它决定了数据去重时所用的算法,如果没有设置该参数,合并时保留分组内的最后一条数据;如果指定了该参数,则保留ver字段取值最大的那一行。
SummingMergeTree: 当合并数据时,会把同一个分区内的具有相同主键的记录合并为一条记录。根据聚合字段设置,该字段的值为聚合后的汇总值,非聚合字段使用第一条记录的值,聚合字段类型必须为数值类型。如果没有指定聚合字段,则会按照非主键的数值类型字段进行聚合
1 | CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] |
SummingMergeTree表引擎依据ORDER BY指定的字段进行聚合,PRIMARY KEY指定主键,但是ORDER BY可以指代主键,一般只声明ORDER BY即可,表数据会按照orderby的维度进行排序,而索引数据会按照主键进行排序生成,索引的顺序必须和表数据对应上,那么含义就是order by的维度中主键必须是最左前缀,下面举一个例子。
假设我们有col1,col2,col3三列,业务上我们只需要对col1进行查询过滤,就是我们只需要col1当做主键,然后根据col1数据以及index_granularity(索引间隔)参数生成我们的索引文件,为了保证数据也是索引的顺序,那么我们应该写order by(col1,col2).
这样带来的好处还有就是主键和维度分开,我们以后可以根据业务情况修改维度
1 | ALTER TABLE test_summing MODIFY ORDER BY (col1,col2,col3); |
AggregatingMergeTree: 在同一数据分区下,可以将具有相同主键的数据进行聚合。
1 | CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] |
与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。对于AggregateFunction类型的列字段,在进行数据的写入和查询时与其他的表引擎有很大区别,在写入数据时,需使用带有 -State- 聚合函数的 INSERT SELECT语句;而在查询数据时,则需要调用相应的-Merge函数。
一般AggregatingMergeTree都是需要和普通的MergeTree进行合用,MergeTree作为底表,防止因为聚合函数错误导致数据丢失,而AggregatingMergeTree作为物化视图,相当于在底表上进行聚合查询
CollapsingMergeTree: 在同一数据分区下,对具有相同主键的数据进行折叠合并。
建表语法:
1 | CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] |
CollapsingMergeTree同样也根据order by字段进行唯一性判定,实际上这种引擎是根据以赠代删的思路,支持行级别修改和删除,通过定义一个sign标记为字段,记录数据行状态,如果sign标记为1,则表示这是一行有效数据,如果sign为-1表示这行数据需要被删除,当分区合并的时候,同一个分区内sign标记为1和-1的一组数据会被抵消删除掉。
分区数据合并折叠不是实时操作,需要在后台实行Compaction操作,用户可以进行手动操作,但是在生产环境中不适合使用效率很低,一般建议group by完毕之和进行having count。eg:
1 | SELECT emp_id,name,sum(salary * sign)FROM emp_collapsingmergetree GROUP BY emp_id, name HAVING sum(sign) > 0; |
上面我们知道了CollapsingMergeTree的合并原理,不难想象,这种合并对写入顺序有着严格要求,否则就会导致数据无法正常折叠,比如我们先写入的是sign=-1的数据,然后再写入sign=1的数据,这时候我们合并分区之和再进行排查依旧是会出现两条数据。
所以这种表结构只适合单线程写入,可以很好地控制顺序写入,但是如果是多线程的状态就不能很好地控制数据写入顺序了,这时候就需要另一种表结构了,就是下面我们要提到的VersionedCollapsingMergeTree
VersionedCollapsingMergeTree:
基于 CollapsingMergeTree 引擎,增添了数据版本信息字段(version)配置选项。在数据依据 ORDER BY 设置对数据进行排序的基础上,如果数据的版本信息列不在排序字段中,那么版本信息会被隐式的作为 ORDER BY 的最后一列从而影响数据排序。
1 | CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] |
version字段会自动的添加到order by末尾,我们在插入数据的之和只要保证同一条数据的version大小,就相当于可以保证它的顺序关系。
GraphiteMergeTree: 用来存储时序数据库 Graphites 的数据。
ClickHouse表引擎种类繁多,其中每一种适合的业务场景都不相同,详细可以参考官方文档 或者一些三方文档,

搭建ClickHouse集群
搭建ClickHouse需要依赖Zookeeper集群,这里我们只在一台机器上搭建Zookeeper,给出Zookeeper,ClickHouse,Kafka版本作参考
| Zookeeper | ClickHouse |
|---|---|
| zookeeper-3.4.10 | 21.8.4.51(21.8.4.51) |
启动Zookeeper并查看状态
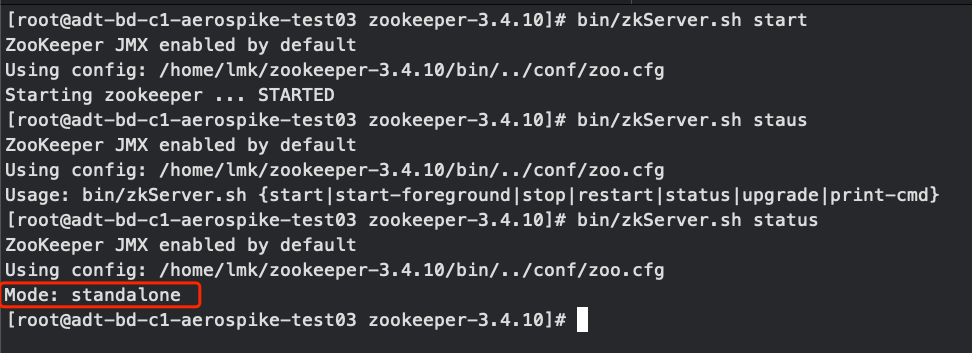
接下来需要在ClickHouse中配置集群信息,在配置之前我们需要明白以下几个关键信息
1.主要读取的配置文件是/etc/clickhouse-server/config.xml
2.ClickHouse会将/etc/clickhouse-server/conf.d/metrika.xml配置文件和上面提到的配置文件合并,但是为了保险,建议还是执行第二条
3.通用的配置信息可以写到metrika.xml配置文件中,如果没有的话需要创建一个,然后在config.xml中引入
1 | <!--引入方法--> |
4.如果上面的方法没有生效,直接修改config.xml文件
5.要清楚你在修改配置文件的哪些地方,我们不管是直接修改config.xml还是写一个metrika.xml文件都是为了修改
了解上面几点之和我们开始配置ClickHouse集群:
修改/etc/clickhouse-server/config.xml
1
2
3
4<!-- 如果禁用了ipv6,使用下面配置 -->
<listen_host>0.0.0.0</listen_host>
<!-- 如果没有禁用ipv6,使用下面配置,我使用的下面的配置 -->
<listen_host>::</listen_host>这个配置是为了我们能正常的登录clickhouse-client,服务器使用了ipv6但是我不小心用了上面的
,登录的时候报错 9000 connection refused,最终定位到了这里。 创建/etc/clickhouse-server/conf.d/metrika.xml文件
根据集群信息,将下面的xml改写成自己集群使用的配置文件,放到对应目录下,需要注意一下几点:
(1)下面xml信息中的集群名称叫做‘doit_ch_cluster1’,可以随意修改,但是要记住名称
(2)
代表分片, 代表副本,一个分片可能有多个副本,集群表也可以有多个分片 (3)下面配置文件集群信息是
标签,注意config.xml中的集群信息叫做什么,一般需要在config.xml中进行一行配置 <remote_servers incl="clickhouse_remote_servers" />,意思相当于标签内容取自 ,其他标签也是一样的,虽然听起来多此一举,但是可以将通用的配置信息摘取出来,之和直接scp给各个服务器就行,但是我两台机器中的一台这样配置一直没有生效。。。没错两台中的一台没有生效,另一台生效了,就很无语,只能将其中的配置直接修改到config.xml中,也算是解决了 (4)macros配置,这个配置创建数据副本表的时候路径可以直接使用宏替换替换,因为我们创建集群表的时候需要保证不同的表以及不同副本在Zookeeper中的路径不同,其中
<shard>标签代表的是我们想让哪几台机器组成一个分片集合,同一个分片的分片名称是一样的比如都是01,或者02,而<replica>标签代表的是本台机器的创建的副本的名称标识,副本是即使是同一个分片的副本名称也不能一样,所以这个副本名称一般采用主机名或者ip,这是需要注意的地方,这块理解起来需要结合官方文档](https://clickhouse.tech/docs/zh/engines/table-engines/mergetree-family/replication/)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66<yandex>
<!-- /etc/clickhouse-server/config.xml 中配置的remote_servers的incl属性值,-->
<clickhouse_remote_servers>
<!-- 集群名称,可以修改 -->
<doit_ch_cluster1>
<!-- 配置三个分片,每个分片对应一台机器,为每个分片配置一个副本 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>master</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<internal_replication>true</internal_replication>
<host>slaver1</host>
<port>9000</port>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>slaver2</host>
<port>9000</port>
</replica>
</shard>
</doit_ch_cluster1>
</clickhouse_remote_servers>
<!-- zookeeper相关配置 -->
<!-- 该标签与config.xml的<zookeeper incl="zookeeper-servers" optional="true" /> 保持一致 -->
<zookeeper-servers>
<node index="1">
<host>master</host>
<port>2181</port>
</node>
<node index="2">
<host>slaver1</host>
<port>2181</port>
</node>
<node index="3">
<host>slaver2</host>
<port>2181</port>
</node>
</zookeeper-servers>
<!-- 分片和副本标识,shard标签配置分片编号,<replica>配置分片副本主机名,需要修改对应主机上的配置 -->
<macros>
<replica>doit01</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>启动ClickHouse集群
我们在ClickHouse机器上都配置完成之后,确保我们的Zookeeper是开启状态,然后重启ClickHouse集群
1
systemctl restart clickhouse-server
确保所有的Clickhouse状态都正常,如果出现问题就去查看一下/var/log/clickhouse/中的err日志
1
systemctl status clickhouse-server
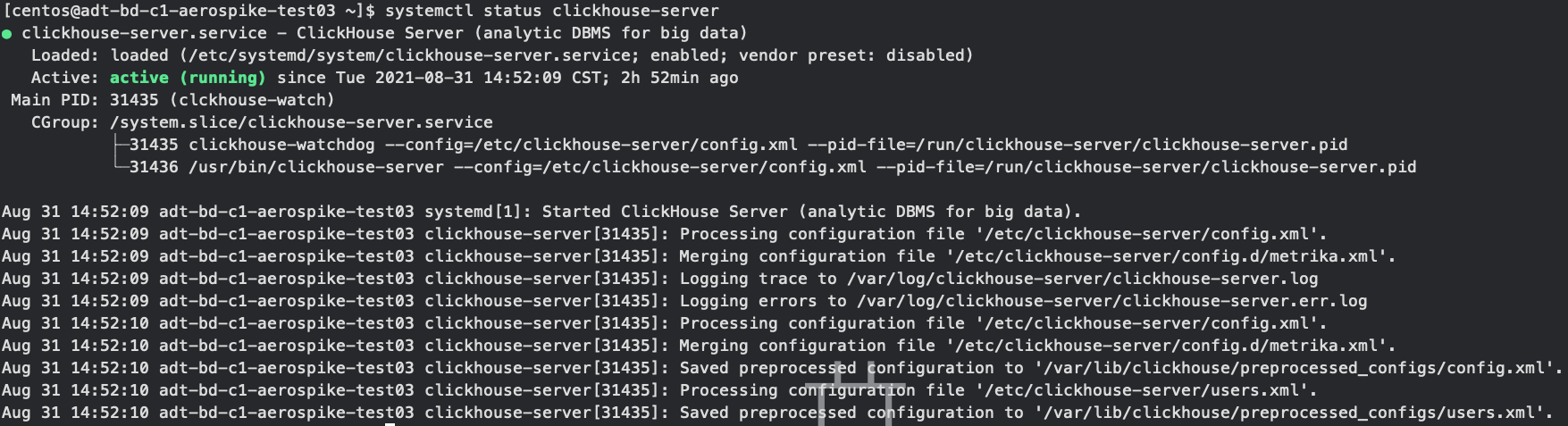
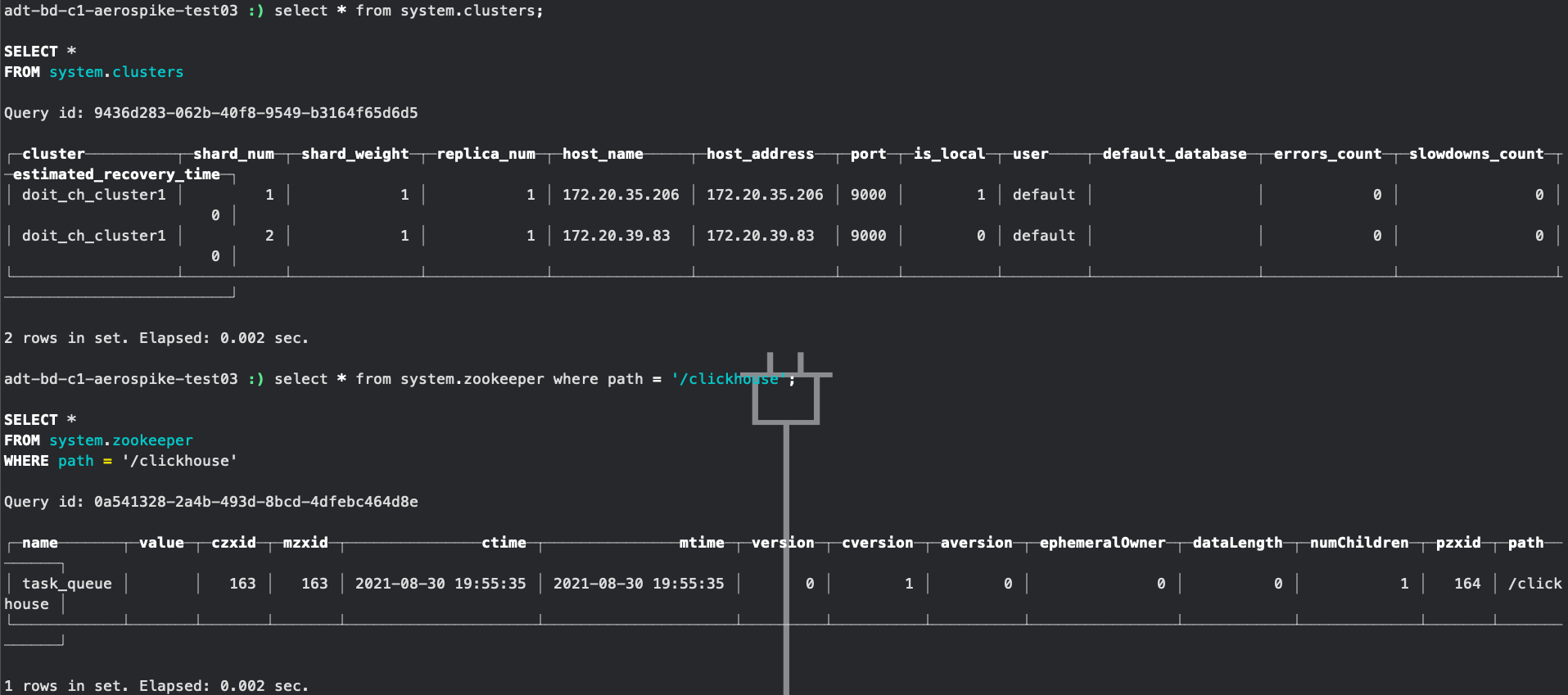
确认所有正常之后我们登录任意一台clickhouse客户端,查看clickhouse集群以及Zookeeper信息,需要注意的是,system.zookeeper表只有在关于Zookeeper配置生效之后才会出现
创建Distribute+Local表
Distribute是Clickhouse比较特殊的一种表引擎,是ClickHouse分布式表的代言词,distribute表引擎创建的表不存储数据,它起到一个路由的作用,将数据路由到集群机器上的本地表。
1 | Distributed(cluster_name, database_name, table_name[, sharding_key]) |
cluster_name:集群名称,与集群配置中的自定义名称相对应。
database_name:数据库名称。
table_name:表名称,需要集群中的机器上都存在这个表
sharding_key:可选的,用于分片的key值,在数据写入的过程中,分布式表会依据分片key的规则,将数据分布到各个节点的本地表,这个参数可选
建立distribute表
1
2
3
4
5
6
7CREATE TABLE IF NOT EXISTS user_cluster ON CLUSTER doit_ch_cluster1
(
id Int32,
name String
)ENGINE = Distributed(doit_ch_cluster1, default, user_local,id);
--上面建表语句代表了数据是要分发到doit_ch_cluster1集群中default.user_local表,根据id决定分发到哪台机器上这里我们为了简单,就只设计两个表字段,其中id是我们用来将数据分到集群机器上的sharding_key,我们也可以用rand()函数让ck随机的决定将数据发送到哪台机器
建立本地表
得益于我们的集群配置,我们可以使用
ON CLUSTER doit_ch_cluster1语法自动在集群中建表,这里我们使用正常的查询引擎MergeTree()1
2
3
4
5
6
7
8
9CREATE TABLE IF NOT EXISTS user_local ON CLUSTER doit_ch_cluster1
(
`id` Int32,
`name` String
)
ENGINE = MergeTree()
PARTITION BY id
PRIMARY KEY id
ORDER BY id
- Post title:Clickhouse 入门与实践
- Post author:刘梦凯
- Create time:2021-08-26 11:09:27
- Post link:https://liumengkai.github.io/2021/08/26/Clickhouse-入门与实践/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.